Bu çalışma, Malatya Klinik Araştırmalar Etik Kurulunun 2016/161 protokol numaralı izni ile onaylanmıştır. Bu araştırmada, anabilim dalımız tarafından Kardiyoloji Anabilim Dalı için geliştirilen PHP tabanlı veri giriş, sorgulama, silme, güncelleme, vb. işlemleri yapan yazılım kullanıldı. Bu kapsamda, Akut Koroner Sendromlu hastalarda DMnin varlığı ve yokluğu, aşağıda belirtilen değişkenlere dayalı olarak sınıflandı. Bu değişkenlere ait tanımlayıcı bilgiler Tablo
1de verilmiştir.
İki grup arası tahmini glikoz düzeyi farkı 20, varsayılan ortak standart sapması 55, tip I hata (alfa) 0.05 ve tip II hata (beta) 0.10 olduğunda, her grupta en az 160 olmak üzere toplamda en az 320 birey gerektiği güç analizi ile hesaplandı5. Bu planlanan araştırma kapsamına 1378 bireye ilişkin veriler alınmıştır.
Bu çalışmada uygulanan veritabanlarında bilgi keşfi (VTBK) süreci aşamaları aşağıda verilmiştir:
a. Veri seçimi: Veritabanlarından elde edilen ve bu araştırmada bağımlı/hedef değişken olarak DM, bağımsız/tahminleyici değişkenler olarak ise Tablo 1de detaylıca açıklanan faktörler veri seçimi kapsamında incelenmiştir.
b. Veri önişleme: Veri setindeki kayıp değer bulunan sınıflar verisetinden çıkarılmıştır. Aşırı/aykırı değer tespiti lokal aykırı faktörü (LOF) analizi ile yapılmış ve tespit edilen aşırı/aykırı değerler verisetinden çıkarılmıştır. Aşırı/aykırı değer tespitinde, yerel aykırı faktör (LOF) algoritması6 kullanıldı. LOF, yakın zamanda geliştirilmiş olan yoğunluğa dayalı aşırı/aykırı gözlem tespitinde kullanılan yöntemlerden biridir. LOF, diğer aşırı/aykırı gözlem saptama algoritmalarıyla karşılaştırıldığında birçok avantaja sahiptir. LOF, bir gözlemin diğer komşu nesnelere olan uzaklığını bir sayısal ölçeğe dönüştürerek, yerel aşırı/aykırı gözlemlerin tespit edilmesini sağlar7.
c. Veri dönüşümü ve veri indirgeme: Veri setindeki sayısal değişkenler için standardizasyon (Z-dönüşümü) uygulanmıştır. Standardizasyona ilişkin denklem aşağıda verilmiştir:
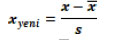
Burada 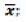
örneklem aritmetik ortalamasını ve
örneklem standart sapmasını ifade etmektedir8.
d. Veri madenciliği: Çeşitli çekirdek fonksiyonları kullanılarak oluşturulan DVM modelleri kullanılarak veri setinden ilişki, örüntüler çıkarma ve tahminler yapılmıştır. Bu çalışmada çeşitli DVM modelleri, Tablo 2de ayrıntılı şekilde tanımlanan değişik çekirdek fonksiyonları ile oluşturulmuş ve incelenen veri setine uygulanmıştır. Hiperparametre optimizasyonu için en yaygın ve en çok bilinen ızgara araması (grid search) yönteminde, hiperpara-metreler tespit edilen sabit bir adım büyüklüğü ile kullanılabilecek olan en büyük aralıkta uygulanır ve her bir sıralanış biçimi (kombinasyon) için performans ölçütlerine göre değerlendirilir9. Tablo 3de DVM modelinin oluşturulmasında kullanılan çekirdek fonksiyonlarının optimizasyon parametreleri, aralıkları ve kombinasyon sayıları verilmiştir.

Büyütmek İçin Tıklayın |
Tablo 3: Çekirdek fonksiyonlarının optimizasyon parametrelerine ilişkin tanımlayıcı bilgiler |
C (cost, maliyet) parametresi, ayırıcı hiperdüzlemin düzgünlüğü ile eğitim verilerinin yanlış sınıflandırılması arasındaki dengeyi kontrol eder10. Maliyet parametresinin aksine σ (sigma), scale (ölçek) ve degree (derece) parametreleri çekirdek fonksiyonu parametreleridir. Sigma; Gaussian RBF, Laplace, ANOVA RBF ve Bessel çekirdek fonksiyonlarının parametresi, ölçek; Hiperbolik Tanjant (Sigmoid) ve Polinomiyal çekirdek fonksiyonlarının parametresi, derece; Polinomiyal, ANOVA RBF ve Bessel çekirdek fonksiyonlarının parametresidir.
e. Değerlendirme ve yorumlama: Çeşitli çekirdek fonksiyonları kullanılarak oluşturulan DVM modellerinin tahmin performansları; 10-katlı çapraz geçerlilik tekniği ile değerlendirilmiştir. Ayrıca, performans metriklerinden doğruluk, duyarlılık, özgüllük (seçicilik) ve ROC eğrisi altında kalan kullanılarak ilgili model çıktıları yorumlanmıştır. Bu metriklere ilişkin ayrıntılı formül tanımlamaları aşağıda verilmiştir:
Doğruluk = (DP+DN)/(DP+DN+YP+YN)
Duyarlılık = DP/(DP+YP)
Özgüllük (Seçicilik) = DN/(DN+YN)
Pozitif tahmin değeri = DP/(DP+YN)
Negatif tahmin değeri =DN/(DN+YP)
Burada; DP: doğru pozitif sayısı, DN: doğru negatif sayısı, YP: yanlış pozitif sayısı, YN: yanlış negatif sayısı olarak tanımlanır.
VTBK sürecindeki analizlerde RStudio Version 1.0.143 yazılımı11 ve yazılım içindeki ilgili paketler kullanılmıştır. Kullanılan paketler; LOF analizi için DMwR12, veri madenciliği aşaması için caret13 ve kernlab14, ROC eğrisi çizimi için ggplot215 ve ROCR16 paketleridir.
Biyoistatistiksel Analiz
Nicel veriler ortalama ve standart sapma, nitel veriler ise sayı ve yüzde özetlendi. Verilerin normal dağılıma uygunluğu Kolmogorov Smirnov testi ve varyansların homojenlik kontrolü ise Levene testi ile değerlendirildi. Verilerin analizinde bağımsız örneklerde t-testi, Pear-son Ki-kare testi, Yates Düzeltilmiş Ki-kare testi ve Fisher Kesin Ki-kare testi uygun olan yerlerde kesin (exact) yaklaşıma dayalı olarak kullanıldı. Analizlerde IBM SPSS Statistics version 24.0 for Windows paket programı17 kullanıldı. p<0.05 değeri istatistiksel olarak önemli kabul edildi.


)
)
)
)
)
)
)